


http://www.wechall.net/challenge/training/programming1/index.php
这道题很显然是考编程,而不是考手速对吧?
访问它那个 this link 也就是这个链接:http://www.wechall.net/challenge/training/programming1/index.php?action=request
可以看到是一串乱码,只需要将那串乱码替换掉 the_message 访问第二个链接即可。
但是它规定要在1.337秒内完成,显然人类的手速没有那么快。所以任务变成:
- Python访问url_1,获得乱码
- Python访问修改过的url_2
但是如果你去尝试过,就会发现,还有一个难点——直接Python访问的话它需要你登录。
于是有两种做法:
- Python登录获得Cookie,再利用这个Cookie访问url_1
- 直接使用浏览器的Cookie,利用这个Cookie访问url_1
显然第二种做法最快捷。所以可以选择法二。
Step 1:找Cookie
以Chrome浏览器为例。获取Cookie的方法一如下。
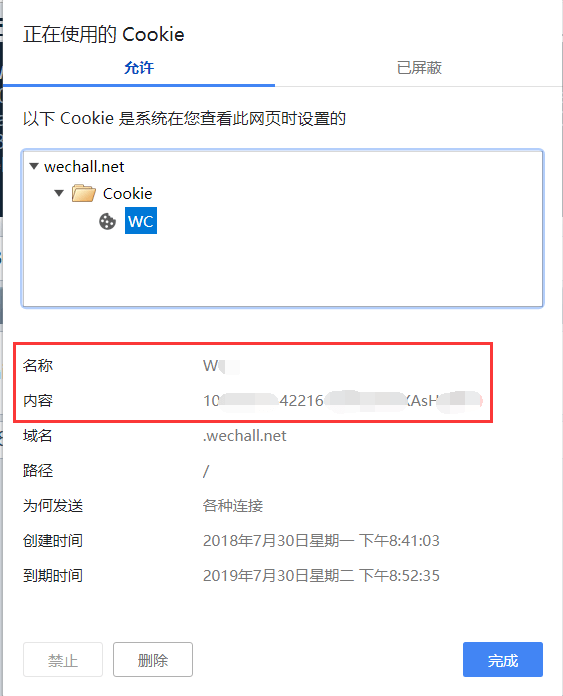
需要注意的一件事是,Cookie包含两个东西,Name和Value,也就是上图的名称和内容,缺一不可。
当然,也可以通过F12打开开发者工具,在Application里面找到当前网站的Cookie,截图略。
Step 2:Programming访问URL
这个才是重头戏。这个是最基础的编程,常用在写爬虫上。只需要用到一个库,urllib。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import urllib.request url_1 = 'http://www.wechall.net/challenge/training/programming1/index.php?action=request' url_2 = 'http://www.wechall.net/challenge/training/programming1/index.php?answer=' header = {} req = urllib.request.Request(url_1,headers = header) req.add_header('Cookie','Name=Value') the_message = urllib.request.urlopen(req).read().decode('utf-8') print(the_message) url_2 = url_2+the_message req = urllib.request.Request(url_2,headers = header) req.add_header('Cookie','Name=Value') html = urllib.request.urlopen(req).read().decode('utf-8') print(html) |
解释一下,Cookie属于Request Header的一部分,通过GET/POST方式发送给服务器实现短时间内的登录。
the_message就是获得的乱码。
访问url_2的时候链接加入了乱码the_message,并加入用于登录的Cookie,最后打印出来的便是告诉你你成功了的界面代码。
‘or 1=1
老哥,不接受在这里练习注入
太强惹